End-to-end Telco Churn Data Engineering Project using Docker, Python, Apache Airflow, PostgreSQL, and Spark. This project automates data ingestion, processing, and storage through a scalable pipeline. Airflow orchestrates the workflow, Spark handles batch processing, and PostgreSQL serves as the primary database.
Dataset: Telco Customer Churn (dibimbing) | Dataset: Telco Customer Churn (Kaggle))
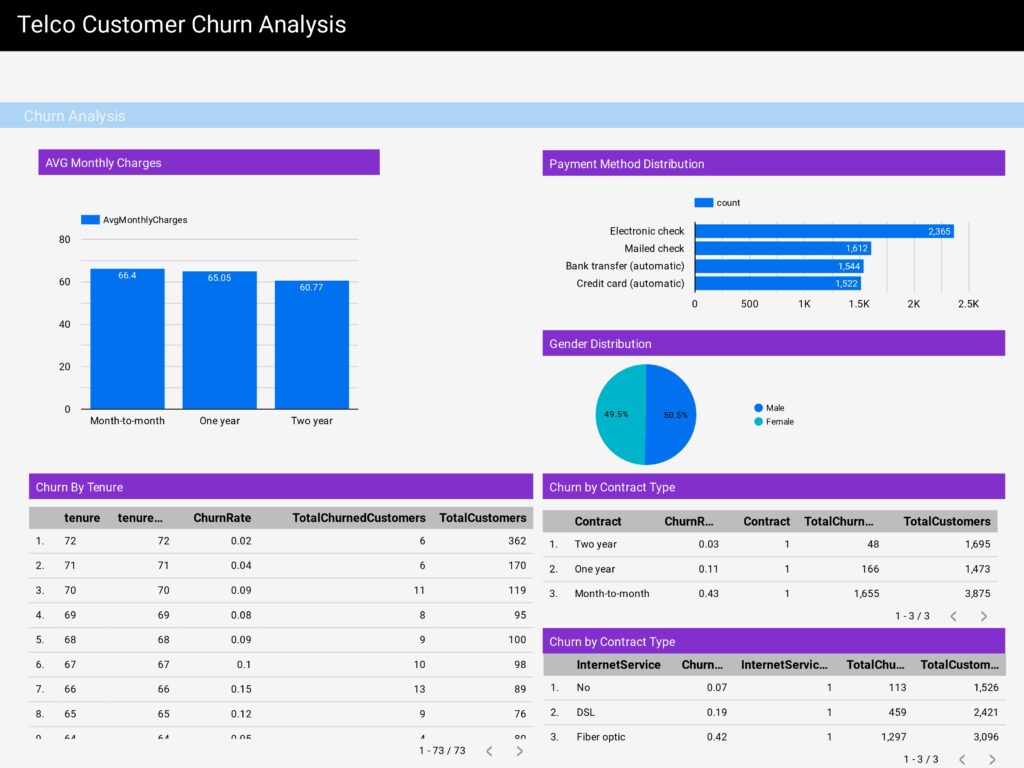
Looker Studio : Telco Customer Churn
Architecture
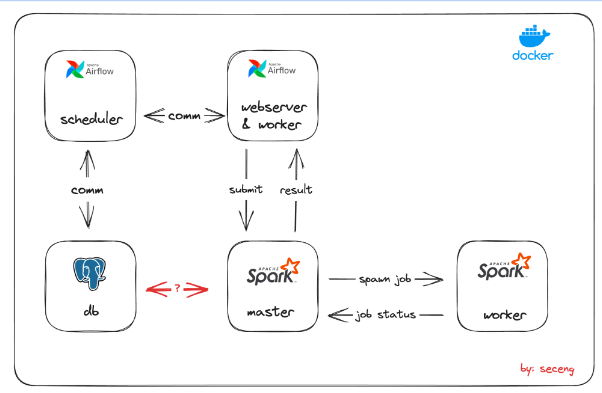
Arsitektur pipeline data untuk analisis churn pelanggan di sektor telekomunikasi menggunakan beberapa komponen utama:
Airflow:
- Scheduler: Mengatur penjadwalan tugas-tugas (tasks) dalam pipeline.
- Webserver & Worker: Mengelola eksekusi dan hasil dari tugas yang dikirimkan ke Spark.
PostgreSQL (db):
- Berfungsi sebagai basis data utama untuk menyimpan data mentah dan hasil transformasi.
- Berkomunikasi dengan Spark untuk mendapatkan data yang dibutuhkan.
Spark Cluster:
- Master: Mengelola eksekusi job dari Spark dan mengirimkan tugas-tugas ke node worker.
- Worker: Memproses tugas yang diberikan oleh master dan mengembalikan status pekerjaan.
Docker:
- Seluruh komponen (Airflow, PostgreSQL, dan Spark) dijalankan dalam container Docker untuk konsistensi lingkungan dan kemudahan dalam deployment.
Data Preprocessing:
- Sebelum melakukan analisis churn, dilakukan preprocessing data terlebih dahulu. Proses ini melibatkan:
- Handling data null: Nilai-nilai yang hilang ditangani dengan metode imputasi median, karena median lebih robust terhadap outlier dibandingkan metode lain.
- Data yang telah diproses ini kemudian siap dimasukkan ke dalam datawarehouse untuk analisis lebih lanjut.
Alur Kerja:
- Airflow berkomunikasi dengan PostgreSQL untuk mengambil data yang dibutuhkan.
- Airflow kemudian mengirimkan tugas ke Spark untuk melakukan preprocessing data, termasuk mengimputasi nilai null dengan median, dan melakukan transformasi data serta analisis churn.
- Spark Master akan mengelola dan membagi tugas ke Spark Worker untuk diproses.
- Hasil pemrosesan dikembalikan ke PostgreSQL atau disimpan sesuai kebutuhan, lalu status pekerjaan dilaporkan kembali ke Airflow untuk menyelesaikan tugas.
- Hasil pemrosesan juga disimpan dalam bentuk CSV di folder result.
- File CSV tersebut kemudian di-load ke Looker untuk visualisasi dan analisis lebih lanjut.
Kesimpulan: Arsitektur ini memungkinkan pipeline yang terstruktur dan scalable untuk proses analisis churn pelanggan di sektor telekomunikasi menggunakan orchestrasi Airflow, pemrosesan batch Spark, dan penyimpanan data dengan PostgreSQL, semuanya dikelola menggunakan Docker. Dengan tambahan proses preprocessing yang mencakup imputasi nilai null menggunakan median dan penyimpanan dalam datawarehouse, hasil analisis menjadi lebih akurat dan siap untuk diolah lebih lanjut. Selain itu, integrasi dengan Looker memungkinkan visualisasi dan pemantauan hasil secara real-time.
DAG for Telco Customer Churn Analysis using Spark
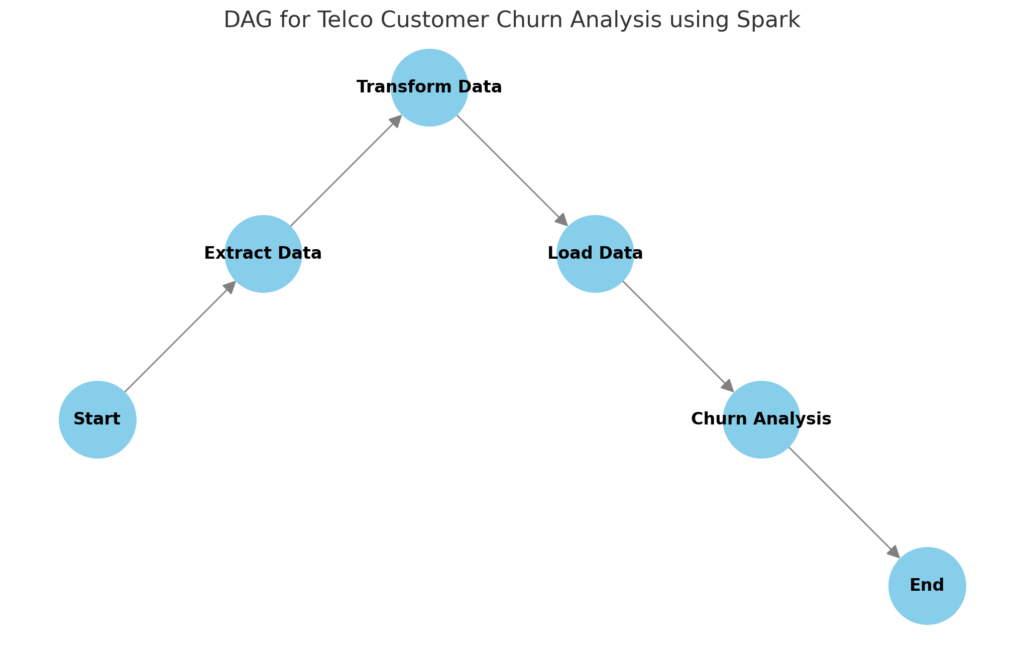
Alur ini mencakup beberapa tahapan utama: Start: Memulai alur proses data pipeline. Extract Data: Mengambil data mentah dari sumber (database atau file). Transform Data: Mengolah dan membersihkan data menggunakan Spark. Load Data: Memuat data yang telah diproses ke dalam database. Churn Analysis: Menganalisis data untuk prediksi churn. End: Mengakhiri alur proses.
Code & Documentation
🔗 Find the complete code and documentation on my GitHub: